Spring Batch
정수원님의 Spring Boot 기반으로 개발하는 Spring Batch 강의를 요약한 내용입니다.
Intro
docker mysql
# download mysql image
docker pull --platform linux/amd64 mysql:8.0.28
# check images
docker images
# create conatiner
docker run --platform linux/amd64 --name mysql -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=1234 mysql:8.0.28
# execute mysql
docker exec -it mysql bash
# root login
mysql -uroot -p1234
# checker process
docker ps
# stop conatiner
docker stop mysql개요
핵심 패턴
Read: 데이터베이스, 파일, 큐에서 다량의 데이터 조회
Process: 특정 방법으로 데이터 가공
Write: 수정된 양식으로 데이터를 다시 저장
아키텍처
Application
모든 배치 Job, 커스텀 코드 포함
업무로직 구현에만 집중하고 공통 기술은 프레임워크가 담당
Batch Core
Job 실행, 모니터링, 관리 API로 구성
JobLauncher, Job, Step, Flow ..
Batch Infrastructure
Application, Core 모두 공통 Infrastructure 위에서 빌드
Job 실행 흐름과 처리를 위한 틀 제공
Reader, Processor Writer, Skip, Retry ..
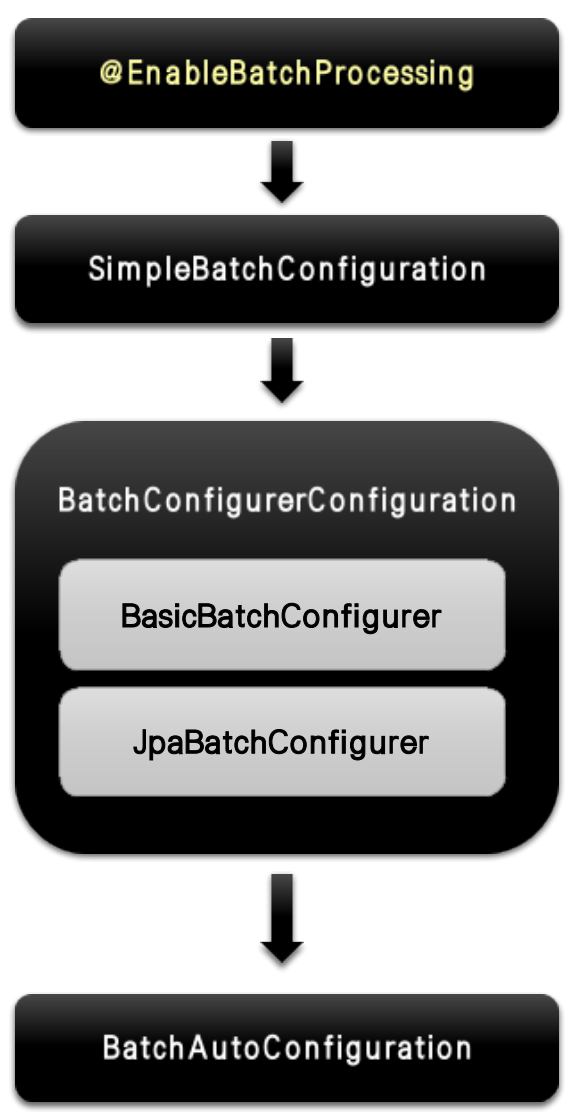
스프링 배치 활성화
@EnableBatchProcessing총 4개의 설정 클래스를 실행시키며 스프링 배치의 모든 초기화 및 실행 구성
BatchAutoConfiguration스프링 배치가 초기화 될 때 자동으로 실행되는 설정 클래스
Job을 수행하는 JobLauncherApplicationRunner 빈 생성
SimpleBatchConfigurationJobBuilderFactory 와 StepBuilderFactory 생성
스프링 배치의 주요 구성 요소 생성 -> 프록시 객체로 생성
BatchConfigurerConfiguration
BasicBatchConfigurerSimpleBatchConfiguration 에서 생성한 프록시 객체의 실제 대상 객체를 생성하는 설정 클래스
빈으로 의존성 주입 받아서 주요 객체들을 참조해서 사용
JpaBatchConfigurerJPA 관련 객체를 생성하는 설정 클래스
스프링 부트 배치의 자동 설정 클래스가 실행됨으로 빈으로 등록된 모든 Job을 검색해서 초기화와 동시에 Job을 수행하도록 구성
{kind=link}
기본 코드
DB 스키마
스프링 배치의 실행/관리를 위한 목적으로 여러 도메인(Job, Step, JobParameters..)의 정보들을 저장/업데이트/조회할 수 있는 스키마 제공
과거, 현재의 실행에 대한 정보, 성공과 실패 여부 등을 관리하여 배치운용 리스크 발생 시 빠른 대처 가능
DB 연동 시 메타 테이블 생성 필수
DB 스키마는 유형별로 제공 (/org/springframework/batch/core/schema-*.sql)
스키마는 수동 또는 자동으로 생성 가능(자동 생성 시 spring.batch.jdbc.initialize-schema 설정)
ALWAYS: 스크립트 항상 실행(RDBMS 설정이 되어 있을 경우 내장 DB 보다 먼저 실행)EMBEDDED: 내장 DB일 때만 실행, 스키마 자동 생성(default)NEVER: 스크립트 항상 실행 안함(내장 DB일경우 스크립트가 생성되지 않으므로 오류 발생)운영에서 수동으로 스크립트 생성 후 설정 권장

관련 테이블
Job 관련 테이블
BATCH_JOB_INSTANCEJob 이 실행될 때 JobInstance 정보가 저장되며 job_name과 job_key를 키로 하여 하나의 데이터가 저장
동일한 job_name 과 job_key 로 중복 저장될 수 없다
1,0,Job,0c5cf62846f98c894b8dce3de3433509
BATCH_JOB_EXECUTIONjob 의 실행정보가 저장되며 Job 생성, 시작, 종료 시간, 실행상태, 메시지 등을 관리
1,2,1,2023-01-23 00:16:14.365000,2023-01-23 00:16:14.452000,2023-01-23 00:16:14.645000,COMPLETED,COMPLETED,"",2023-01-23 00:16:14.646000,
BATCH_JOB_EXECUTION_PARAMSJob과 함께 실행되는 JobParameter 정보를 저장
2,STRING,name,user1,1970-01-01 09:00:00,0,0,Y
2,LONG,seq,"",1970-01-01 09:00:00,1,0,Y
2,DATE,date,"",2023-01-23 00:16:14.666000,0,0,Y
2,DOUBLE,age,"",1970-01-01 09:00:00,0,29.5,Y
BATCH_JOB_EXECUTION_CONTEXTJob 의 실행동안 여러가지 상태정보, 공유 데이터를 직렬화 (Json 형식) 해서 저장
Step 간 서로 공유 가능함
1,"{""@class"":""java.util.HashMap""}",
Step 관련 테이블
BATCH_STEP_EXECUTIONStep 의 실행정보가 저장되며 생성, 시작, 종료 시간, 실행상태, 메시지 등을 관리
1,3,step1,1,2023-01-23 00:16:14.507000,2023-01-23 00:16:14.551000,COMPLETED,1,0,0,0,0,0,0,0,COMPLETED,"",2023-01-23 00:16:14.552000
BATCH_STEP_EXECUTION_CONTEXTStep 의 실행동안 여러가지 상태정보, 공유 데이터를 직렬화 (Json 형식) 해서 저장
Step 별로 저장되며 Step 간 서로 공유할 수 없음
1,"{""@class"":""java.util.HashMap"",""batch.taskletType"":""io.springbatch.springbatchlecture.job.JobConfiguration$1"",""batch.stepType"":""org.springframework.batch.core.step.tasklet.TaskletStep""}",
스프링 배치 도메인
Job
Job
배치 계층 구조에서 가장 상위에 있는 개념으로 하나의 배치작업 자체를 의미
Job Configuration 을 통해 생성되는 객체 단위로, 배치작업을 어떻게 구성하고 실행할 것인지 전체적으로 설정하고 명세해 놓은 객체
배치 Job 구성을 위한 최상위 인터페이스, 스프링 배치가 기본 구현체 제공
여러 Step 을 포함하는 컨테이너, 반드시 한 개 이상의 Step으로 구성
기본 구현체
SimpleJob
순차적으로 Step 을 실행시키는 Job
모든 Job에서 유용하게 사용할 수 있는 표준 기능을 갖음
FlowJob
특정한 조건과 흐름에 따라 Step 을 구성하여 실행시키는 Job
Flow 객체를 실행시켜서 작업을 진행

JobInstance
BATCH_JOB_INSTANCE
Job 실행 시(SimpleJob) 생성되는 Job 의 논리적 실행 단위 객체 (고유하게 식별 가능한 작업 실행을 나타냄)
Job 과 설정/구성은 동일하지만, Job 실행 시점에 처리하는 내용은 다르므로 Job 실행 구분이 필요
ex. 하루 한 번씩 배치 Job이 실행된다면, 매일 실행되는 각각의 Job 을 JobInstance 로 표현
JobInstance 생성 및 실행
처음 시작 : [Job + JobParameter] 의 새로운 JobInstance 생성
이전과 동일한 [Job + JobParameter] 으로 실행 : 이미 존재하는 JobInstance 리턴 -> 예외 발생 및 배치 실패
JobName + jobKey(jobParametes 의 해시값) 가 동일한 데이터는 중복 저장 불가
Job : 1 - JobInstance : N

JobParameters
BATCH_JOB_EXECUTION_PARAMS
job 실행 시 함께 포함되어 사용되는 파라미터를 가진 도메인 객체
하나의 Job에 존재할 수 있는 여러개의 JobInstance 구분
JobParameters : 1 - JobInstance : 1
생성 및 바인딩
어플리케이션 실행 시 주입
Java -jar LogBatch.jar requestDate(date)=2021/01/01 name=user seq(long)=2L age(double)=29.5
코드로 생성
JobParameterBuilder, DefaultJobParametersConverter
SpEL 이용
@Value(“#{jobParameter[requestDate]}”), @JobScope, @StepScope 선언 필수
JOB_EXECUTION : 1 - BATCH_JOB_EXECUTION_PARAM : N
실행 시 Arguments : job.name=JobParameter date(date)=2021/01/01 name=user seq(long)=2L age(double)=29.5

JobExecution
BATCH_JOB_EXECUTION
JobIstance(동일한 JobParameter)에 대한 한번의 시도를 의미하는 객체
Job 실행 중 발생한 정보들을 저장 -> 시작시간, 종료시간, 상태(시작/완료/실패), 종료상태
JobExecution 은 'FAILED' 또는 'COMPLETED‘ 등의 Job 실행 결과 상태를 가지고 있음
실행 상태 결과가 'COMPLETED’ 일 경우, JobInstance 실행이 완료된 것으로 간주해서 재 실행 불가
실행 상태 결과가 'FAILED’ 일 경우, JobInstance 실행이 완료되지 않은 것으로 간주해서 재실행 가능
실행 상태 결과가 'COMPLETED’ 될 때까지 하나의 JobInstance 내에서 여러 번의 시도 발생 가능
BATCH_JOB_INSTANCE : 1 - BATCH_JOB_EXECUTION : N관계로서
JobInstance 에 대한 성공/실패의 내역을 보유
JobExecution.java

Step
Step
Batch job을 구성하는 독립적인 하나의 단계
실제 배치 처리를 정의하고 컨트롤하는데 필요한 모든 정보를 가지고 있는 도메인 객체
단순한 단일 태스크 뿐 아니라, 입력, 처리, 출력 관련 복잡한 비즈니스 로직을 포함하는 모든 설정들을 담음
배치작업을 어떻게 구성하고 실행할 것인지 Job의 세부 작업을 Task 기반으로 설정하고 명세
모든 Job은 하나 이상의 step으로 구성
기본 구현체
TaskletStep
가장 기본이 되는 클래스. Tasklet 타입 구현체들을 제어
직접 생성한 Tasklet 실행
ChunkOrientedTasklet 을 실행
PartitionStep
멀티 스레드 방식으로 Step을 여러 개로 분리해서 실행
JobStep
Step 내에서 Job 실행
FlowStep
Step 내에서 Flow 실행

StepExecution
BATCH_STEP_EXECUTION
Step에 대한 한 번의 시도를 의미하는 객체 (Step 실행 중 발생한 정보들을 저장)
시작시간, 종료시간, 상태(시작,완료,실패), commit count, rollback count 등의 속성을 가짐
Step이 매번 시도될 때마다 생성되며 각 Step 별로 생성
Job이 재시작 하더라도 이미 완료된 Step은 재실행되지 않고 실패한 Step만 실행
이전 단계 Step이 실패해서 현재 Step을 실행하지 않았다면 StepExecution을 생성하지 않고, 시작되었을 때만 StepExecution 생성
JobExecution
Step의 StepExecution 이 모두 정상적으로 완료되어야 JobExecution 정상 완료(COMPLETED)
Step의 StepExecution 중 하나라도 실패하면 JobExecution 실패(FAILED)
BATCH_JOB_EXECUTION : 1 - BATCH_STEP_EXECUTION : N
StepExecution.java

Job: 하나의 배치작업 자체 (두 개의 Step으로 구성)
JobInstance: Job 실행 시 생성되는 Job 의 논리적 실행 단위 객체
JobExecution: JobIstance 에 대한 한번의 시도를 의미하는 객체
StepExecution: Step에 대한 한 번의 시도를 의미하는 객체
StepContribution
청크 프로세스의 변경 사항을 버퍼링 한 후 StepExecution 상태를 업데이트하는 도메인 객체
청크 커밋 직전에 StepExecution apply 메서드를 호출하여 상태를 업데이트
ExitStatus 기본 종료코드 외 사용자 정의 종료코드를 생성해서 적용 가능
StepContribution.java

ExecutionContext
BATCH_STEP_EXECUTION_CONTEXT, BATCH_STEP_EXECUTION_CONTEXT
프레임워크에서 유지/관리하는 키/값 컬렉션
StepExecution 또는 JobExecution 객체의 상태 저장 공유 객체
DB에 직렬화된 값으로 저장 (ex. { “key” : “value”})
공유 범위
Step: 각 Step의 StepExecution에 저장되며 Step 간 서로 공유 불가
Job: 각 Job의 JobExecution에 저장되며 Job 간 서로 공유 불가하지만, 해당 Job의 Step 간 서로 공유 가능
Job 재시작 시 이미 처리한 Row 데이터는 건너뛰고, 이후 수행 시 상태 정보 활용
ExecutionContext.java
ExecutionContext 와 Job, Step 정보 조회

JobRepository
배치 작업 정보를 저장하는 저장소
Job의 수행, 종료, 실행 횟수, 결과 등 배치 작업의 수행과 관련된 모든 meta data 저장
JobLauncher, Job, Step 구현체 내부에서 CRUD 기능 처리
@EnableBatchProcessing 선언 시 자동으로 빈 생성
BatchConfigurer 인터페이스 구현, BasicBatchConfigurer 상속으로 JobRepository 설정 커스터마이징 가능
JDBC 방식 설정: JobRepositoryFactoryBean
내부적으로 AOP 기술을 통해 트랜잭션 처리
트랜잭션 isolation 기본값은 최고 수준인 SERIALIZEBLE (다른 레벨로 지정 가능)
메타테이블의 Table Prefix 변경 가능 (기본 값은 "BATCH_")
In Memory 방식 설정 – MapJobRepositoryFactoryBean
성능 등 이유로 도메인 오브젝트를 데이터베이스에 저장하고 싶지 않을 경우
보통 Test, 프로토타입 빠른 개발 시 사용
JobRepository interface
JobLauncher
배치 Job을 실행시키는 역할
Job, Job Parameters를 인자로 받아 요청된 배치 작업 수행 후 최종 client 에게 JobExecution 반환
스프링 부트 배치가 구동되면 JobLauncher Bean 자동 생성
Job 실행
JobLanucher.run(Job, JobParameters)
스프링 부트 배치에서 JobLauncherApplicationRunner가 자동으로 JobLauncher 실행
동기적 실행
taskExecutor를 SyncTaskExecutor로 설정 시(default. SyncTaskExecutor)
JobExecution 획득 후, 배치 처리를 최종 완료한 이후 Client에게 JobExecution 반환
배치 처리 시간이 길어도 상관없거나, 스케줄러에 의한 배치처리에 적합
비동기적 실행
taskExecutor가 SimpleAsyncTaskExecutor로 설정할 경우
JobExecution 획득 후, Client에게 바로 JobExecution 반환 및 배치처리 완료
배치처리 시간이 길 경우 응답이 늦어지지 않도록 하고, HTTP 요청에 의한 배치처리에 적합
스프링 배치 실행
Job
배치 초기화 설정
JobLauncherApplicationRunner
Spring Batch 작업을 시작하는 ApplicationRunner(BatchAutoConfiguration에서 생성)
스프링 부트 제공 ApplicationRunner 구현체로 어플리케이션 정상 구동 후 실행
기본적으로 빈으로 등록된 모든 job 실행
BatchProperties
Spring Batch 환경 설정 클래스
Job name, 스키마 초기화 설정, 테이블 Prefix 등을 설정
application.yml
Job 실행 옵션
지정한 Batch Job만 실행하도록 설정 가능
spring.batch.job.names: ${job.name:NONE}
Program arguments 사용 시
JobBuilderFactory
JobBuilder 를 생성하는 팩토리 클래스
jobBuilderFactory.get("jobName") : 스프링 배치가 Job 실행 시 참조하는 Job 이름
JobBuilder
Job 구성 설정 조건에 따라 두 개의 하위 빌더 클래스를 생성하고 실제 Job 생성 위임
SimpleJobBuilder
SimpleJob 을 생성하는 Builder 클래스
Job 실행 관련 여러 설정 API 제공
FlowJobBuilder
FlowJob 을 생성하는 Builder 클래스
내부적으로 FlowBuilder 를 반환하며 Flow 실행 관련 여러 설정 API 제공

JobBuilderFactory 클래스 상속 구조

SimpleJob
JobBuilderFactory > JobBuilder > SimpleJobBuilder > SimpleJob
Step 을 실행시키는 Job 구현체(SimpleJobBuilder 에 의해 생성)
여러 단계의 Step 으로 구성할 수 있으며 Step 을 순차적으로 실행
모든 Step 실행이 성공적으로 완료되어야 Job 이 성공적으로 완료
맨 마지막 실행 Step 의 BatchStatus 가 Job 의 최종 BatchStatus
SimpleJob API
jobBuilderFactory.
get("batchJob") // JobBuilder 생성 팩토리, Job 이름을 - 매개변수로.
start(Step) // 처음 실행 할 Step 설정, 최초 한번 설정, 실행 시 SimpleJobBuilder 반환.
next(Step) // 다음 실행 할 Step 설정, 횟수는 제한 없으며 모든 next()의 Step이 종료되면 Job 종료.
incrementer(JobParametersIncrementer) // Job 실행마다 JobParameter 값 자동 증가 설정JobParameters 의 필요한 값을 증가시켜 다음 사용될 JobParameters 오브젝트 리턴
기존 JobParameter 변경없이 Job 을 여러 번 시작하고자 할 경우 사용
RunIdIncrementer 구현체를 지원하며 인터페이스 직접 구현 가능
.
preventRestart(true) // Job 재시작 가능 여부 설정 (default. true)Job 재시작 여부 설정
Job 실행이 처음이 아닌 경우 Job 성공/실패와 상관없이 preventRestart 설정에 따라 실행 여부 판단
.
validator(JobParameterValidator) // 실행 전 JobParameter 검증 설정DefaultJobParametersValidator 구현체 지원. 인터페이스 직접 구현 가능
Job Repository 생성 전(SimpleJobLauncher), Job 수행 전(AbstractJob) 검증
.
listener(JobExecutionListener) // Job 라이프 사이클의 특정 시점에 콜백을 - 제공받도록 설정.build(); // SimpleJob 생성

Step
StepBuilderFactory
StepBuilder 를 생성하는 팩토리 클래스
StepBuilder
Step 을 구성하는 설정 조건에 따라 다섯 개의 하위 빌더 클래스 생성 및 실제 Step 생성 위임
TaskletStepBuilder
TaskletStep 을 생성하는 기본 빌더 클래스
SimpleStepBuilder
TaskletStep 을 생성하며 내부적으로 청크기반의 작업을 처리하는 ChunkOrientedTasklet 클래스 생성
PartitionStepBuilder
PartitionStep 을 생성하며 멀티 스레드 방식으로 Job 실행
JobStepBuilder
JobStep 을 생성하여 Step 안에서 Job 실행
FlowStepBuilder
FlowStep 을 생성하여 StTaskletStepep 안에서 Flow 실행


TaskletStep
StepBuilderFactory > StepBuilder > TaskletStepBuilder > TaskletStep
Step 구현체. Tasklet 을 실행시키는 도메인 객체
RepeatTemplate 을 사용해서 Tasklet 구문을 트랜잭션 경계 내에서 반복 실행
Step 의 실행 단위로 Task 기반과 Chunk 기반으로 나누어서 Tasklet 실행
chunk 기반
하나의 큰 덩어리를 N개씩 나눠서 실행. 대량 처리에 효과적
ItemReader, ItemProcessor, ItemWriter 를 사용하며 청크 기반 전용 Tasklet 인 ChunkOrientedTasklet 구현체 제공
Task 기반
청크 기반 작업 보다 단일 작업 기반 처리에 효율적
주로 Tasklet 구현체를 만들어 사용
대량 처리 시 chunk 기반에 비해 더 복잡한 구현 필요

stepBuilderFactory.
get(“batchStep") : StepBuilder 생성 팩토리.
tasklet(Tasklet) : Tasklet 클래스 설정(Task 기반), TaskletStepBuilder 반환Step 내에서 구성되고 실행되는 도메인 객체(주로 단일 태스크 수행)
TaskletStep 에 의해 반복적으로 수행되며 반환값(RepeatStatus)에 따라 반복 혹은 종료
Step 에 오직 하나의 Tasklet 설정 가능
.<String, String>
chunk(100) : Chunk 기반.
startLimit(10) (default. INTEGER.MAX_VALUE)Step 실행 횟수 설정, 설정한 만큼 실행되고 초과시 오류(StartLimitExceededException) 발생
.
allowStartIfComplete(true)Step 성공, 실패 상관없이 항상 Step 실행을 위한 설정
실행 마다 유효성을 검증하거나, 사전 작업이 꼭 필요한 Step 등 적용
.
listener(StepExecutionListener) : Step 라이프 사이클 특정 시점에 콜백 설정.
build(); : TaskletStep 생성

JobStep
Job 에 속하는 Step 중 외부의 Job 을 포함하고 있는 Step
외부 Job 실패 시 해당 Step 이 실패하므로 결국 최종 기본 Job 도 실패
메타데이터는 기본 Job, 외부 Job 별로 각각 저장
커다란 시스템을 작은 모듈로 분리하고 job 흐름을 관리할 경우 사용
.
stepBuilderFactory
.get("jobStep") : StepBuilder 생성 팩토리.job(Job) : JobStep 내에서 실행 될 Job 설정(JobStepBuilder 반환).launcher(JobLauncher) : Job 을 실행할 JobLauncher 설정.parametersExtractor(JobParametersExtractor) : Step의 ExecutionContext를 Job이 실행되는 데 필요한 JobParameters로 변환.build() : JobStep 을 생성
Flow
FlowJob
JobBuilderFactory > JobBuilder > JobFlowBuilder > FlowBuilder > FlowJob
Step 순차적 구성이 아닌 특정 상태에 따라 흐름을 전환하도록 구성 (FlowJobBuilder에 의한 생성)
Step이 실패 하더라도 Job 은 실패로 끝나지 않도록 해야 하는 경우
Step이 성공 했을 때 다음에 실행해야 할 Step 을 구분해서 실행 해야 하는 경우
특정 Step은 전혀 실행되지 않도록 구성 해야 하는 경우
Flow, Job 흐름을 구성하는데만 관여하고 실제 비즈니스 로직은 Step 에서 수행
내부적으로 SimpleFlow 객체를 포함하고 있으며 Job 실행 시 호출
Flow(start, from, next)는 흐름을 정의하는 역할을 하고, 나머지 Transition는 조건에 따라 흐름을 전환시키는 역할
jobBuilderFactory
.get(“batchJob").start(Step) : 처음 실행 Step or Flow 설정flow 설정 시 JobFlowBuilder 반환
step 설정 시 SimpleJobBuilder 반환
.on(String pattern)Step 실행 결과로 돌려받는 종료상태(ExitStatus)를 매칭(TransitionBuilder 반환)
ExitStatus 매칭이 되면 다음으로 실행할 Step 지정 가능
특수문자는 두 가지만 허용(*, ?)
.to(Step)다음으로 실행할 Step
.from(Step)이전 단계에서 정의한 Step Flow 추가 정의
.stop()/.fail()/.end()/.stopAndRestart()Flow 중지/실패/종료 수행
.next(Step) : 다음으로 이동할 StepStep or Flow or JobExecutionDecider
.end() : build() 앞에 위치하면 FlowBuilder 종료 및 SimpleFlow 객체 생성.build() : FlowJob 생성 및 flow 필드에 SimpleFlow 저장

Transition
Flow 내 Step 조건부 전환 정의
on(String pattern) 메소드 호출 시 TransitionBuilder를 반환하여 Transition Flow 구성
Step 종료상태(ExitStatus)가 pattern과 매칭되지 않으면 스프링 배치에서 예외 발생 및 Job 실패
구체적인 것부터 그렇지 않은 순서로 적용
on(), to(), stop()/fail()/end()/stopAndRestart()
stop()
FlowExecutionStatus STOPPED 상태로 종료
Job의 BatchStatus, ExitStatus STOPPED으로 종료
fail()
FlowExecutionStatus FAILED 상태로 종료
Job의 BatchStatus, ExitStatus FAILED으로 종료
end()
FlowExecutionStatus COMPLETED 상태로 종료
Job의 BatchStatus, ExitStatus COMPLETED으로 종료
Step의 ExitStatus가 FAILED 이더라도 Job의 BatchStatus가 COMPLETED로 종료하도록 가능지만 Job 재시작은 불가능
stopAndRestart(Step or Flow or JobExecutionDecider)
stop() transition과 기본 흐름은 동일
특정 step에서 작업을 중단하도록 설정하면 중단 이전의 Step만 COMPLETED 저장되고 이후의 step은 실행되지 않고 STOPPED 상태로 Job 종료
Job 재실행 시 실행해야 할 step을 restart 인자로 넘기면 이전에 COMPLETED로 저장된 step은 건너뛰고 중단 이후 step부터 시작
배치 상태 유형
BatchStatus
JobExecution, StepExecution 속성으로 Job, Step 종료 후 최종 결과 상태 정의
SimpleJob
마지막 Step의 BatchStatus 값을 Job 최종 BatchStatus 값으로 반영
Step 실패 시 해당 Step이 마지막 Step
FlowJob
Flow 내 Step의 ExitStatus 값을 FlowExecutionStatus 값으로 저장
마지막 Flow의 FlowExecutionStatus 값을 Job의 최종 BatchStatus 값으로 반영
ExitStatus
JobExecution, StepExecution의 속성으로 Job, Step 실행 후 종료 상태 정의
기본적으로 ExitStatus는 BatchStatus와 동일한 값으로 설정
SimpleJob
마지막 Step의 ExitStatus 값을 Job 최종 ExitStatus 값으로 반영
FlowJob
Flow 내 Step 의 ExitStatus 값을 FlowExecutionStatus 값으로 저장
마지막 Flow의 FlowExecutionStatus 값을 Job의 최종 ExitStatus 값으로 반영
FlowExecutionStatus
FlowExecution 속성으로 Flow 실행 후 최종 결과 상태 정의
Flow 내 Step 이 실행되고 ExitStatus 값을 FlowExecutionStatus 값으로 저장
FlowJob 배치 결과 상태에 관여
사용자 정의 ExitStatus
ExitStatus에 존재하지 않는 exitCode를 새롭게 정의
StepExecutionListener의 afterStep() 메서드에서 Custom exitCode 생성 후 새로운 ExitStatus 반환
Step 실행 후 완료 시점에서 현재 exitCode를 사용자 정의 exitCode로 수정 가능
JobExecutionDecider
ExitStatus를 조작하거나 StepExecutionListener를 등록할 필요 없이 Transition 처리를 위한 전용 클래스
Step, Transiton 역할을 명확히 분리
Step의 ExitStatus가 아닌 JobExecutionDecider의 FlowExecutionStatus 상태값을 새롭게 설정해서 반환

SimpleFlow
JobBuilderFactory > FlowJobBuilder > FlowBuilder > SimpleFlow
Flow 구현체로서 각 요소(Step, Flow, JobExecutionDecider)들을 담고 있는 State를 실행시키는 도메인 객체
FlowBuilder로 생성하며 Transition과 조합하여 여러 개의 Flow 및 중첩 Flow를 만들어 Job 구성 가능
jobBuilderFactory
.get("flowJob").start(flow1()) : Flow 정의.on("COMPLETED").to(flow2()) : Flow를 transition과 함께 구성.end(): SimpleFlow 객체 생성.build(): FlowJob 객체 생성

SimpleFlow Architecture
StateMap에 저장되어 있는 모든 State들의 handle 메서드를 호출해서 모든 Step 들이 실행되도록 함
현재 호출되는 State가 어떤 타입인지 관심 없고, handle 메소드를 실행하고 상태값을 얻어온다.(상태 패턴)


FlowStep
Step 내에 Flow를 할당하여 실행시키는 도메인 객체
flowStep의 BatchStatus와 ExitStatus는 Flow 최종 상태값에 따라 결정
StepBuilderFactory > StepBuilder > FlowStepBuilder > FlowStep
stepBuilderFactory
.get(“flowStep").flow(flow()) : Step 내에서 실행 될 flow 설정(FlowStepBuilder 반환).build(); : FlowStep 객체 생성

Scope
스프링 컨테이너에서 빈이 관리되는 범위
singleton, prototype, request, session, application (default. singleton)
Spring Batch Scope
@JobScope, @StepScope
Job, Step 의 빈 생성과 실행에 관여
Proxy 객체의 실제 대상이 되는 Bean 등록/해제 역할
실제 빈을 저장하고 있는 JobContext, StepContext 소유
내부적으로 빈 Proxy 객체 생성
@Scope(value = "job", proxyMode = ScopedProxyMode.TARGET_CLASS)
@Scope(value = "step", proxyMode = ScopedProxyMode.TARGET_CLASS)
어플리케이션 구동 시점에는 빈의 프록시 객체가 생성되어 실행 시점에 실제 빈을 호출(AOP)
JobContext, StepContext
스프링 컨테이너에서 생성된 빈을 저장하는 컨텍스트 역할
Job 실행 시점에서 프록시 객체가 실제 빈 참조에 사용
해당 스코프가 선언되면 빈 생성이 어플리케이션 구동시점이 아닌 빈 실행시점에
@Values 주입으로 빈 실행 시점에 값을 참조할 수 있으며, Lazy Binding 가능
@Value("#{jobParameters[파라미터명]}"), @Value("#{jobExecutionContext[파라미터명]”}), @Value("#{stepExecutionContext[파라미터명]”})
@Values 사용 시 빈 선언문에 @JobScope, @StepScope 를 정의하지 않으면 오류 발생
병렬처리 시 각 스레드 마다 생성된 스코프 빈이 할당되기 때문에 스레드에 안전하게 실행 가능
@JobScope
Step 선언문에 정의
@Value : jobParameter, jobExecutionContext 만 사용 가능
@StepScope
Tasklet, ItemReader, ItemWriter, ItemProcessor 선언문에 정의
@Value : jobParameter, jobExecutionContext, stepExecutionContext 사용 가능

스프링 배치 청크 프로세스
Chunk
여러 개의 아이템을 묶은 하나의 덩어리(블록)
한번에 하나씩 아이템을 입력 받아 Chunk 단위의 덩어리로 만든 후 Chunk 단위로 트랜잭션 처리
Chunk 단위의 Commit / Rollback 수행
일반적으로 대용량 데이터를 한 번에 처리하는 것이 아닌 청크 단위로 쪼개어서 처리할 경우 사용
Chunk<I> vs Chunk<O>
Chunk<I>: ItemReader로 읽은 하나의 아이템을 Chunk에서 정한 개수만큼 반복해서 저장Chunk<O>: ItemReader로부터 전달받은Chunk<I>를 참조해서 ItemProcessor에서 적절하게 가공/필터링한 후 ItemWriter에 전달

ChunkOrientedTasklet
Tasklet 구현체로 Chunk 지향 프로세싱 담당
ItemReader, ItemWriter, ItemProcessor 를 사용해 Chunk 기반 데이터 입출력 처리
TaskletStep 에 의해 반복적으로 실행되며 ChunkOrientedTasklet 이 실행 될 때마다 매번 새로운 트랜잭션이 생성되어 처리가 이루어짐
exception 발생 시, 해당 Chunk는 롤백 되며 이전에 커밋한 Chunk 는 완료 상태 유지
내부적으로 ItemReader 를 핸들링 하는
ChunkProvider, ItemProcessor, ItemWriter 를 핸들링하는ChunkProcessor타입 구현체를 가짐

StepBuilderFactory > StepBuilder > SimpletepBuilder > TaskletStep
stepBuilderFactory.get("chunkStep")
<I, O>chunk(10) : chunk size(commit interval) 설정
<I, O>chunk(CompletionPolicy) : chunk 프로세스를 완료하기 위한 정책 설정 클래스
reader(itemReader()) : 소스로 부터 item을 읽거나 가져오는 ItemReader 구현체
writer(itemWriter()) : item을 목적지에 쓰거나 보내기 위한 ItemWriter 구현체
processor(itemProcessor()) : item 변형/가공/필터링을 위한 ItemProcessor 구현체
stream(ItemStream()) : 재시작 데이터를 관리하는 콜백에 대한 스트림
readerIsTransactionalQueue() : Item이 JMS, Message Queue Server와 같은 트랜잭션 외부에서 읽혀지고 캐시할 것인지 여부(default. false)
listener(ChunkListener) : Chunk 프로세스가 진행되는 특정 시점에 콜백 제공받도록 ChunkListener 설정
ChunkProvider
ItemReader 로 Chunk size 만큼 아이템을 읽어서 Chunk 단위로 만들어 제공
Chunk<I> 를 만들고 내부적으로 반복문을 사용해서 ItemReader.read() 를 계속 호출하며 item 을 Chunk 에 적재
외부로 부터 호출될 때마다 항상 새로운 Chunk 생성
반복문 종료 시점
Chunk size 만큼 item 을 읽으면 반복문 종료되고 ChunkProcessor 로 전달
ItemReader 가 읽은 item 이 null 일 경우 반복문 종료 및 해당 Step 반복문까지 종료
기본 구현체로서 SimpleChunkProvider, FaultTolerantChunkProvider 존재
ChunkProcessor
ItemProcessor 로 Item 변형/가공/필터링하고 ItemWriter 로 Chunk 데이터 저장/출력
Chunk<O> 를 만들고 앞에서 넘어온 Chunk<I> 의 item 을 한 건씩 처리한 후 Chunk<O> 에 저장
외부로 부터 호출될 때마다 항상 새로운 Chunk 생성
ItemProcessor 는 설정 시 선택사항으로서 객체가 존재하지 않을 경우 ItemReader 에서 읽은 item 그대로가 Chunk<O> 에 저장
ItemProcessor 처리가 완료되면 Chunk<O> 에 있는 List<Item> 을 ItemWriter 에게 전달
ItemWriter 처리가 완료되면 Chunk 트랜잭션이 종료되고 Step 반복문에서 ChunkOrientedTasklet 가 새롭게 실행
ItemWriter 는 Chunk size 만큼 데이터를 Commit 처리하므로 Chunk size 는 곧 Commit Interval
기본 구현체로서 SimpleChunkProcessor, FaultTolerantChunkProcessor 존재
ItemReader
다양한 입력으로부터 데이터를 읽어서 제공
csv, txt, xml, json, database, MQ, Custom Reader
ChunkOrientedTasklet 실행 시 필수 요소
T read()
입력 데이터를 읽고 다음 데이터로 이동
아이템 하나를 리턴하며 더 이상 아이템이 없는 경우 null 리턴
더 이상 처리해야 할 Item 이 없어도 예외가 발생하지 않고 ItemProcessor 와 같은 다음 단계로 이동
.
다수의 구현체들이 ItemReader, ItemStream 인터페이스를 동시에 구현
파일의 스트림, DB 커넥션을 열거나 종료, 입력 장치 초기화 등의 작업
ExecutionContext 에 read 와 관련된 여러가지 상태 정보를 저장해서 재시작 시 다시 참조 하도록 지원
일부를 제외하고 하위 클래스들은 기본적으로 스레드에 안전하지 않기 때문에 병렬 처리시 데이터 정합성을 위한 동기화 처리 필요(JdbcPagingItemRedaer, JpaPagingItemReader 는 스레스 안전)

ItemWriter
Chunk 단위로 데이터를 받아 일괄 출력 작압
csv, txt, xml, json, database, MQ, Custom Reader
ChunkOrientedTasklet 실행 시 필수 요소
void write(List<? extends T> items)
출력 데이터를 아이템 리스트로 받아 처리
출력이 완료되고 트랜잭션이 종료되면 새로운 Chunk 단위 프로세스로 이동
.
다수의 구현체들이 ItemWriter, ItemStream 동시 구현
파일의 스트림을, DB 커넥션을 열거나 종료, 출력 장치 초기화 등의 작업
보통 ItemReader 구현체와 1:1 대응 관계인 구현체들로 구성

ItemProcessor
데이터 출력 전에 데이터 가공/변형/필터링
ItemReader, ItemWriter 와 분리되어 비즈니스 로직 구현
ItemReader 로 받은 아이템을 변환해서 ItemWriter 에 전달
ItemReader 로 받은 아이템들 중 필터 과정을 거쳐 원하는 아이템들만 ItemWriter 에 전달 가능
ItemProcessor 에서 process() 실행결과 null을 반환하면 Chunk<O> 에 저장되지 않기 때문에 ItemWriter에 전달되지 않음
ChunkOrientedTasklet 실행 시 선택 요소
O process
아이템 하나씩 가공하며 null 리턴 시 해당 아이템은 Chunk<O> 에 저장되지 않음
.
ItemStream 을 구현하지 않음
대부분 Customizing 하여 사용하므로 기본적으로 제공되는 구현체가 적음

ItemReader, ItemProcessor, ItemWriter
ItemStream
ItemReader, ItemWriter 처리 과정 중 상태를 저장하고 오류가 발생하면 해당 상태를 참조하여 실패한 곳에서 재시작 하도록 지원
리소스를 open/close 를 통해 입출력 장치 초기화 등의 작업
open : 리소스 열고 초기화, 최초 1회
update : 현재 상태정보 저장, Chunk size 만큼 반복
cloas : 모든 리소스 닫음
ExecutionContext 를 매개변수로 받아 상태 정보를 업데이트
ItemReader, ItemWriter 는 ItemStream 구현 필요

ItemReader vs ItemProcessor
ItemReader 에서 Chunk size 만큼 Item 을 한 개씩 모두 읽은 다음 ItemProcessor 에게 전달하면 읽은 Item 개수 만큼 반복 처리
반복 및 오류 제어
Repeat
스프링 배치는 작업을 얼마나 반복해야 하는지 알려 줄 수 있는 기능 제공
특정 조건이 충족 될 때까지(또는 특정 조건이 아직 충족되지 않을 때까지) Job 또는 Step 을 반복하도록 구성 가능
스프링 배치에서는 Step, Chunk 반복을 RepeatOperation 을 사용해서 처리
기본 구현체로 RepeatTemplate 제공
반복 종료 여부 항목
RepeatStatus
스프링 배치의 처리가 끝났는지 판별하기 위한 enum
CONTINUABLE(남은 작업 존재), FINISHED(더 이상 반복 없음)
CompletionPolicy
RepeatTemplate iterate 메소드 안에서 반복 중단결정
실행 횟수 또는 완료시기, 오류 발생 시 수행 할 작업에 대한 반복여부 결정
정상 종료를 알리는데 사용
ExceptionHandler
RepeatCallback 안에서 예외가 발생하면 RepeatTemplate 가 ExceptionHandler 를 참조해서 예외를 다시 던질지 여부 결정
예외를 받아서 다시 던지게 되면 반복 종료
비정상 종료를 알리는데 사용

FaultTolerant
Job 실행 중 오류 발생 시 장애 처리를 위한 기능을 제공 -> 이를 통해 복원력 향상
오류가 발생해도 Step 이 즉시 종료되지 않고, Retry 혹은 Skip 기능을 활성화 함으로써 내결함성 서비스 가능
내결함성을 위해 Skip, Retry 기능 제공
Skip : ItemReader / ItemProcessor / ItemWriter 에 적용 가능
Retry : ItemProcessor / ItemWriter 에 적용 가능
FaultTolerant 구조는 청크 기반의 프로세스 기반위에 Skip, Retry 기능이 추가되어 재정의
StepBuilderFactory > StepBuilder > FaultTolerantStepBuilder > TaskletStep

Skip
데이터를 처리하는 동안 설정된 Exception 발생 시, 해당 데이터 처리를 건너뛰는 기능
데이터의 사소한 오류에 대해 Step 실패처리 대신 Skip을 통해 배치수행의 빈번한 실패 감소
오류 발생 시 스킵 설정에 의해서 Exception 발생 건은 건너뛰고 다음 건부터 다시 처리
ItemReader는 예외 발생 시 해당 아이템만 스킵하고 계속 진행
ItemProcessor, ItemWriter는 예외 발생 시 Chunk 처음으로 돌아가서 스킵된 아이템을 제외한 나머지 아이템들을 가지고 처리
스킵 정책에 따라 아이템의 skip 여부를 판단한하는 클래스(SkipPolicy 구현체)
AlwaysSkipItemSkipPolicy : 항상 Skip
ExceptionClassifierSkipPolicy : 예외대상을 분류하여 skip 여부를 결정
CompositeSkipPolicy : 여러 SkipPolicy 탐색하면서 skip 여부를 결정
LimitCheckingItemSkipPolicy : Skip 카운터 및 예외 등록 결과에 따라 skip 여부를 결정(default)
NeverSkipItemSkipPolicy : skip 하지 않음

Retry
ItemProcess, ItemWriter 에서 설정된 Exception 발생 시 지정한 정책에 따라 데이터 처리를 재시도하는 기능
Skip과 마찬가지로 Retry를 통해 배치수행의 빈번한 실패 감소
오류 발생 시 재시도 설정에 의해서 Chunk 단계 처음부터 다시 시작
아이템은 ItemReader에서 캐시로 저장한 값 사용
재시도 정책에 따라 아이템의 retry 여부를 판단한하는 클래스(RetryPolicy 구현체)
AlwaysRetryPolicy : 항상 재시도를 허용
ExceptionClassifierRetryPolicy : 예외대상을 분류하여 재시도 여부를 결정
CompositeRetryPolicy : 여러 RetryPolicy 를 탐색하면서 재시도 여부를 결정
SimpleRetryPolicy : 재시도 횟수 및 예외 등록 결과에 따라 재시도 여부를 결정(default)
MaxAttemptsRetryPolicy : 재시도 횟수에 따라 재시도 여부를 결정
TimeoutRetryPolicy : 주어진 시간동안 재시도를 허용
NeverRetryPolicy : • 최초 한번만 허용하고 그 이후로는 허용하지 않음

Skip & Retry Architecture
ItemReader

ItemProcessor

ItemWriter

Multi Thread Processing
작업 처리에 있어서 단일 스레드, 멀티 스레드의 선택 기준은 어떤 방식이 자원을 효율적으로 사용하고 성능처리에 유리한가의 차이
일반적으로 복잡한 처리나 대용량 데이터를 다루는 작업일 경우 전체 소요 시간 및 성능상의 이점을 가져오기 위해 멀티 스레드 방식을 선택 (비동기 처리 및 Scale out 기능 제공)
멀티 스레드 처리 방식은 데이터 동기화 이슈가 존재 하기 때문에 최대한 고려해서 결정 필요

AsyncItemProcessor / AsyncItemWriter
ItemProcessor 에게 별도의 스레드가 할당되어 작업을 처리(Step 안에서 ItemProcessor 가 비동기적으로 동작)
AsyncItemProcessor, AsyncItemWriter 가 함께 구성 필요
AsyncItemProcessor 로부터 AsyncItemWriter 가 받는 최종 결과값은
List<Future<T>>타입이며 비동기 실행이 완료될 때까지 대기spring-batch-integration 의존성 필요


AsyncItemProcessor / AsyncItemWriter
Multi-threaded Step
Step 내에서 멀티 스레드로 Chunk 기반 처리(ItemReader, ItemProcessor, ItemWriter)가 이루어지는 구조
TaskExecutorRepeatTemplate 이 반복자로 사용되며 설정한 개수(throttleLimit) 만큼의 스레드를 생성하여 수행
Thread-safe ItemReader 로 JdbcPagingItemReader 또는 JpaPagingItemReader 활용

Remote Chunking
분산환경처럼 Step 처리가 여러 프로세스로 분할되어 외부의 다른 서버로 전송되어 처리
Parallel Steps
Step 마다 스레드가 할당되어 여러개의 Step을 병렬로 실행
SplitState 를 사용해서 여러 개의 Flow 들을 병렬적으로 실행하는 구조
실행 완료 후 FlowExecutionStatus 결과들을 취합해서 다음 단계 결정
Partitioning
MasterStep이 SlaveStep 을 실행시키는 구조
SlaveStep은 각 스레드에 의해 독립적으로 실행
SlaveStep은 독립적인 StepExecution 파라미터 환경을 구성
SlaveStep은 ItemReader/ItemProcessor/ItemWriter 등을 가지고 동작하며 작업을 독립적으로 병렬 처리
MasterStep은 PartitionStep이며 SlaveStep은 TaskletStep, FlowStep 등이 올 수 있음


SynchronizedItemStreamReader
Thread-safe 하지 않은 ItemReader를 Thread-safe하게 처리하도록 지원(Spring Batch 4.0 부터)
Event Listener
배치 흐름 중 Job/Step/Chunk 단계의 실행 전후에 발생하는 이벤트를 받아 용도에 맞게 활용할 수 있도록 제공
각 단계별로 로그를 남기거나 소요된 시간을 계산하거나 실행상태 정보들을 참조 및 조회 가능
이벤트를 받기 위해 Listener 등록이 필요하며 등록은 API 설정에서 각 단계별로 지정 가능
어노테이션 방식과 인터페이스 구현 방법 존재
.
Job
JobExecutionListener : Job 실행 전/후
Job 성공여부와 상관없이 호출
JobExecution를 통해 성공/실패 여부 확인 가능
Step
StepExecutionListener : Step 실행 전/후
Step 성공여부와 상관없이 호출
StepExecution를 통해 성공/실패 여부 확인 가능
ChunkListener : Chunk(Tasklet) 실행 전/후, 오류 시점
ItemReadListener : ItemReader 실행 전/후, 오류 시점, item null 일 경우 호출 안됨
ItemProcessListener : ItemProcessor 실행 전/후, 오류 시점, item null 일 경우 호출 안됨
ItemWriteListener : ItemWriter 실행 전/후, 오류 시점, item null 일 경우 호출 안됨
JobExecutionListener / StepExecutionListener
ChunkListener/ItemReadListener/ItemProcessListener/ItemWriteListener
Skip
SkipListener : 읽기, 쓰기, 처리 Skip 실행 시점, Item 처리가 Skip 될 경우 Skip 된 item 추적
Retry
RetryListener : Retry 시작, 종료, 에러 시점

SkipListener

RetryListener

Test
@SpringBatchTest
dependency: spring-batch-test
ApplicatonContext에 테스트에 필요한 여러 유틸 Bean을 자동으로 등록
JobLauncherTestUtils
launchJob(), launchStep()과 같은 스프링 배치 테스트에 필요한 유틸성 메서드 지원
JobRepositoryTestUtils
JobRepository를 사용해서 JobExecution 생성/삭제 메서드 지원
StepScopeTestExecutionListener
@StepScope 컨텍스트를 생성. 해당 컨텍스트를 통해 JobParameter 등을 단위 테스트에서 DI 받을 수 있도록 지원
JobScopeTestExecutionListener
@JobScope 컨텍스트를 생성. 해당 컨텍스트를 통해 JobParameter 등을 단위 테스트에서 DI 받을 수 있도록 지원
Operation
JobExplorer
JobRepository readonly 버전
실행중인 Job 실행 정보인 JobExecution 또는 Step 실행 정보인 StepExecution 조회 가능
JobRegistry
생성된 Job 자동 등록, 추적, 관리하며 여러 곳에서 job을 생성한 경우 ApplicationContext에서 job을 수집해서 사용 가능
기본 구현체로 map 기반의 MapJobRegistry 클래스 제공
jobName을 Key로, job을 value로 매핑
Job 등록
JobRegistryBeanPostProcessor – BeanPostProcessor 단계에서 bean 초기화 시 자동으로 JobRegistry에 Job 등록
JobOperator
JobExplorer, JobRepository, JobRegistry, JobLauncher 을 포함하며, 배치의 중단, 재시작, job 요약 등의 모니터링 가능
기본 구현체로 SimpleJobOprerator 클래스 제공
Application
마무리
도메인 이해 : JobInstance, JobExecution, StepExecution, ExecutionContext, JobParameter, JobRepository, JobLauncher
Job 구성 및 API 활용 : Job, Step, Flow, Tasklet
Chunk 프로세스 : Chunk, ItemReader, ItemProcessor, ItemWriter
반복 및 내결함성 : Repeat, Skip, Retry, Listener
이벤트 리스너 : JobExecutionListener, StepListener, RetriyListner, SkipListener
멀티 스레드 배치 처리 : MultiThread Batch Process
테스트 및 운영 : TDD & JobExeplorer, JobRegistry, JobOperator
필요 시 추가 수강
스프링 배치 청크 프로세스 활용 ItemReader / ItemWriter / ItemProcessor
Last updated